多处理机系统
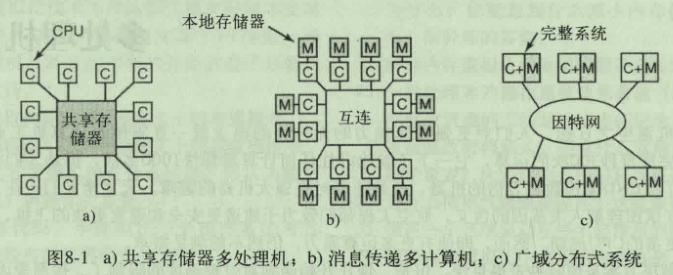
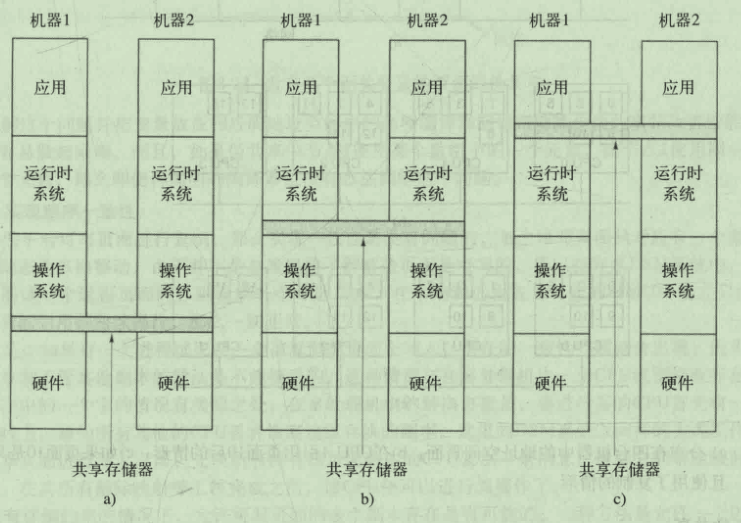
三种类型的多处理机系统
- a:共用一个物理存储器 对程序员透明
- b:没有全局共享屋里存储器 编程较困难
- c:通过网络连接起来的分布式系统
多处理机
多个CPU共享访问一个公用RAM
多处理机硬件
统一存储器访问(UMA)
基于总线的UMA多处理机体系结构
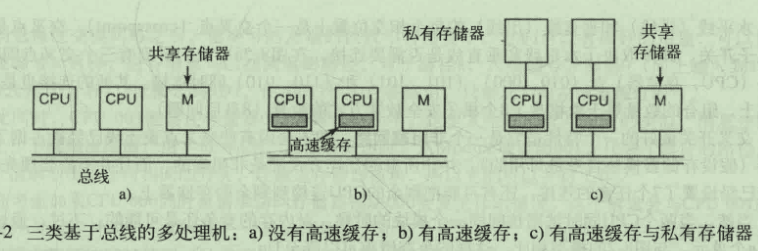
没有高速缓存就需要在数据写入是进行总线冲突检测,这样系统会 受到总线带宽的限制,加上缓存或者私有存储器 总线流量就大大减少 可以支持更多的CPU
使用交叉开关的UMA多处理机
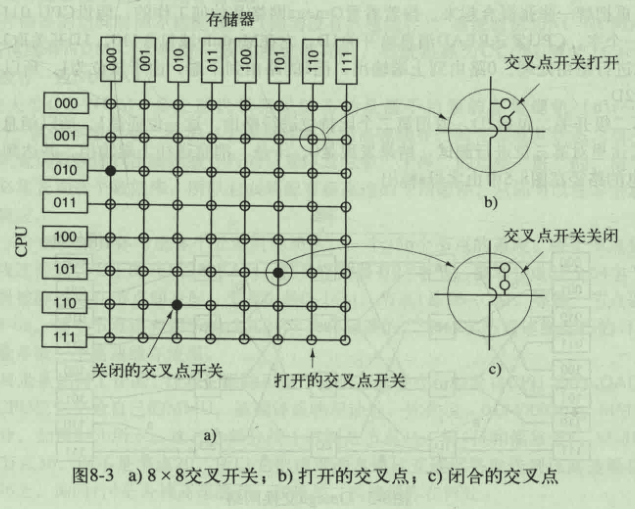
这种方式两个处理器对同一个存储器的竞争将降低到1/n
但交叉点的数量是处理器的平方倍
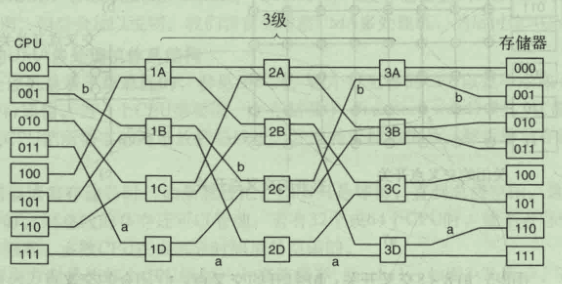
使用多级交换网络的UMA多处理机
通过一个开关来避免交叉点的平方倍上升

NUMA多处理机
- 具有对所有CPU可见的单个地址空间
- 拥有远程与本地存储器
多核芯片
多个核心之间共享内存 内存与各个核心的高速缓存会通过某些协议来实现一致性 多核芯片也被称为片级多处理机
被称为Soc(片上系统)的多核芯片不仅包含多个通用核心,而且还会嵌入若干个专用核心,如音视频解码
众核芯片
由数量众多的核心组成的芯片
适用于众核芯片的编程模型已被正面的有消息传递和分布式内存 维护内存一致性的代价很大
如GPU就是众核芯片,适合大量并行的小规模计算 GPU本质上是单指令多数据流处理器
异构多核
统一芯片包含着多个不同架构不同指令集的异构核心
多处理机操作系统类型
每个CPU有自己的操作系统
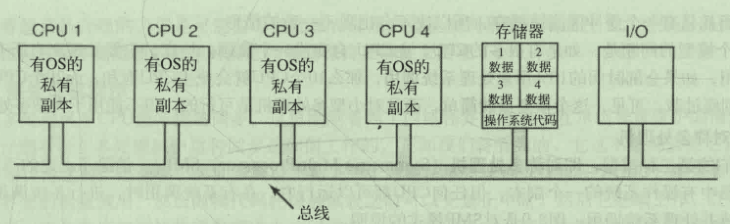
每个CPU都可以共享内存与IO资源
但是可能造成资源使用不均衡 但最要命的是各个CPU都要各自维护自己的磁盘缓冲区 就会造成不一致的情况
主从多处理机
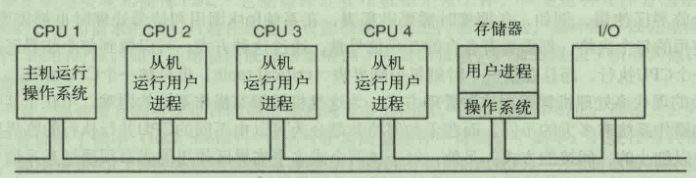
所有的系统调用都要经过主CPU 主CPU会成为瓶颈 对小型多处理机是可行的
对称多处理机
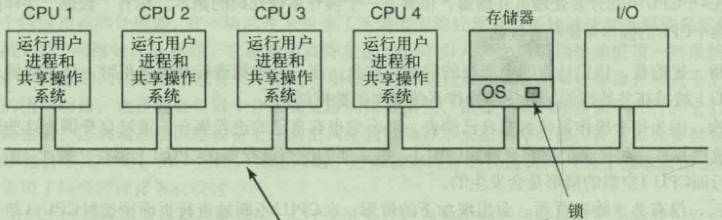
一种方式是任何时刻都只能有一个CPU运行操作系统
另一种方式是将操作系统分割成互不影响的临界区 不同的CPU处理不同的功能 实现并行操作
多处理机同步
TSL(test and set lock)
必须先锁住总线 然后再进行读写访问
但这样如果冲突过于频繁 总线有效流量负载就大大下降 为了解决这个问题:
- 锁总线之前使用一个纯读操作测试总线是否空闲
- 发生冲突时,使用二进制指数回退算法
- 更好的方法是,发生冲突后,每个CPU等待的时间都不同 以避免再次冲突
自旋还是切换 当操作系统的某个线程获取不到互斥信号量时 是进行自旋还是切换到另外一个线程?
许多研究都是选择自旋一段时间 超过某个阈值 就进行切换
现代处理器都提供了特殊的指令使得等待过程更加高效
多处理机调度
分时
现在的发展趋势是内核选择线程为调度单位
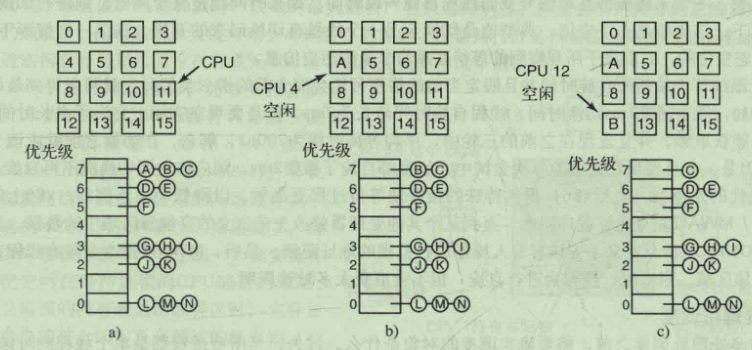
智能调度:为了避免线程在时间片用完后没有释放锁 调度程序会给予其稍微多一点的时间片以完成临界区的工作以释放锁
亲和调度:如果一个CPU运行过某个任务,那么下次调度这个任务会优先选择这个CPU以充分利用高速缓存
空间共享
当一个进程的多个线程之间频繁通信 让它们在同一时间执行就显得很重要
群调度
- 把一组相关相关线程作为一个单位进行调度
- 一个群中的相关线程在不同的分时CPU上同时运行
- 群组所有成员共同开始和结束时间片
多计算机
如果将CPU数量进一步增加,不仅造价高昂,而且实现起来也更困难
所以通过互联网络及接口卡来实现多计算机之间的通信
多计算机硬件
互连技术
- 存储转发包交换
这种类型的交换技术需要将消息分解成包,以包为基础传输单位,但存在着网络时延增加的问题
- 电路交换
比特流直接从源传递到目的地,没有中间缓冲区。
网络接口
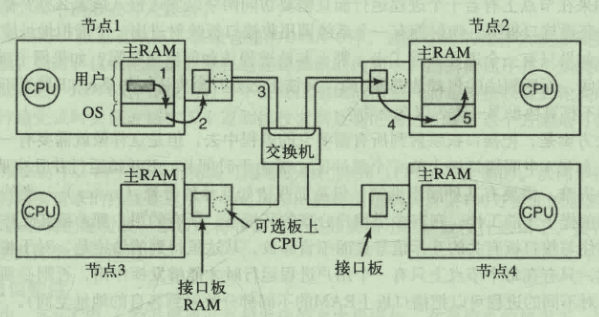
网卡都有属于自己的私有RAM 这样设计的原因在于网络上的比特流速率一般都是恒定的,如果不进行及时同步存储比特数据,就会有数据丢失的风险
现在网卡的功能日益强大,引入了网络处理器来将主CPU的一些功能分担给网卡
低层通信软件
进出RAM的复制是高性能通信的瓶颈,所以许多计算机都把网卡映射到用户空间(零拷贝),允许用户程序直接把包发送到网卡而不经过内核。
但当多个用户进程需要访问卡时,如何确保每个进程都能获取?
较新的网卡通常都是多队列的,这意味着可以有效支持多个用户进程。并且这些队列具有亲和性,较常使用某个队列的进程会优先获得这个队列。
- 节点至网络接口通信
可以采取将页面钉住,禁止系统将其交换,这样可以避免发送的过程中发送页面交换带来的严重后果。
- 远程直接内存访问
允许一台机器直接访问另一台机器的内存
用户层通信软件
- 发送和接收
通信服务以调用的进行展现
send(dest, &msg); // 发送
recv(addr, &msg); // 接收
需要考虑编址问题,也就是dest和addr的地址组成,一种可能的解决方案是使用CPU编号加上实际的内存地址来实现。
- 阻塞调用和非阻塞调用
非阻塞调用可能会出现消息传输过程时,缓冲区被重写了。
在发送端有如下解决方案:阻塞发送 带有复制操作的非阻塞发送 带有中断操作的非阻塞操作 写时复制
另外一种选择就是异步调用,当成功接收到消息后,就会启动一个线程或者子程序来对消息进行处理
远程过程调用(RPC)
许多人认为基于IO的编程是一种错误的编程模型。
RPC对程序员透明
对于被调用的过程,参数类型会被限制 如无法使用指针。同时全局变量也无法使用
分布式共享存储器(DSM)
- 复制只读页面来改善性能
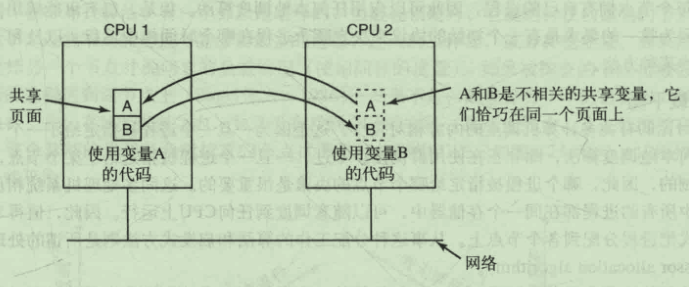
- 伪共享
多处理机中,高速缓存块通常为32字节或64字节,由于局部性原理这样一次读取到CPU缓存可以有效提升性能
另一方面,在分布式共享存储器中,缓存的单位为页面,页面越大,就越有可能发生伪共享问题。伪共享指的是同一页面里的多份数据由于变动频繁,在CPU之间传递来传递去。这与在Java中两个相邻变量加上volatile会影响性能道理是一样的。 Java volatile
- 实现顺序一致性
多处理机通过CPU在写入前发出一个信号,通知其他CPU丢弃缓存副本来实现一致性。这里DSM的实现也是类似。
另外一种解决方法是加一把地址空间锁,对某个地址只允许一个CPU操作,当锁被释放后,将产生的修改传播到其他副本。
多计算机调度
决定进程在哪个节点上运行,也就是预先分配,是调度的重点
负载均衡
使用什么算法分配哪些节点调度哪些进程
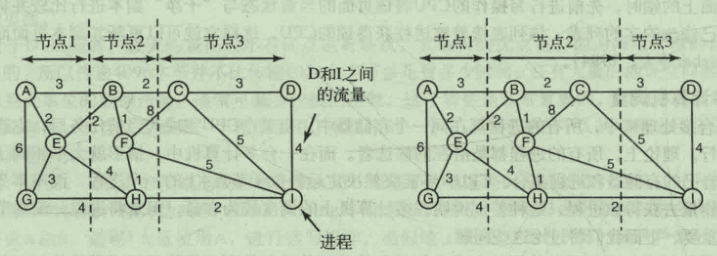
- 图论确定算法
每个节点代表一个进程 每个弧代表进程间的流量
- 发送者发起的分布式启发算法
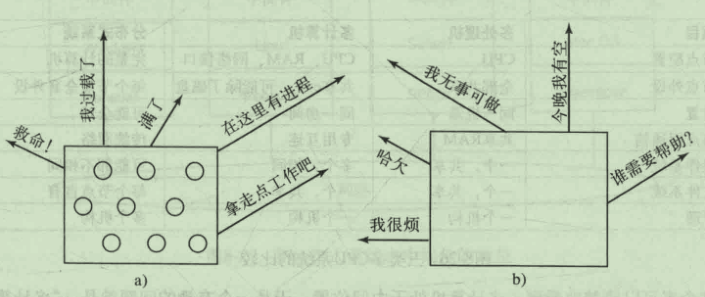
当某个节点负载过重,就会寻找负载不重的节点来接替它的部分工作。
这种算法在所有节点的负载都很重的情况下所有节点都会进行尝试查找接替节点,这样的尝试会带来巨大的开销
- 接受者发起的分布式启发算法
这种算法与上面的算法相反,机器一旦空闲下来就会去找工作做。
但在系统空闲的时候就会产生大量流量,不过相比系统负载过重的时候产生大量流量,这个结果好多了。